
A true story: 47 days from a daily average of 30,000 IP to zero
Last April, I received a WeChat from Lao Zhang, who is a digital reviewer. He only sent five words: “The whole site is cool, save me. “The accompanying picture is a screenshot of Google Analytics - the average daily IP fell off a cliff from 30,000 to 47, a time span of exactly 47 days. This is not an algorithmic misstep, but the standard ending of that March 2024 Google core update.
That update lasted a full 45 days, from March 5 to April 19, and was the longest core algorithm tweak in Google's history. I've personally experienced the 2018 Medic Update and survived the 2021 Page Experience, but a 45-day deployment cycle is unheard of. More critically, this time it's not a simple signal weight adjustment, but ratherHelpful Content system officially integrated into Core Ranking System--This means that the removal of low-quality AI content is no longer an ”extracurricular activity” of a separate module, but has become the core logic of the ranking algorithm.
Old Zhang's website is a typical victim. At the end of 2023, he used AI tools to batch-generate 800 articles of “Best Cost-Effective Headphones Recommendation“, each of which was neatly structured, with perfect keyword density, but without any actual test data, real wearing experience, or even unpacking the box. This kind of content in the old algorithm may be able to rely on information stacking to get by, but in the new system, the algorithm through theNeural Network Feature DetectionPatterned features of the text were identified - the overly perfect H2 heading hierarchy, the lack of fluctuating narrative rhythms of human experience, and the flawless grammatical structure were instead evidence of “inhuman creativity“.
You think this is two years old? No, the storm has just escalated.
On February 5, 2026, Google initiated its first proprietary core update for the Discover feature, which was deployed only on February 27, a period of 22 days. After this update, the number of unique domains in the US Discover Top 1000 plummeted from 172 to 158, further intensifying the header concentration effect. The algorithm is no longer just penalizing obvious spam, but has begun to systematically lower the exposure threshold for “AI content that lacks depth and expertise“ - even if your article is grammatically correct and informative, as long as it reads like it's smoothly interpolated from training data, rather than from the real world. Even if your article is grammatically correct and informative, as long as it reads like it was smoothly interpolated from training data rather than polished from real-world friction, the indexing priority will be discounted.
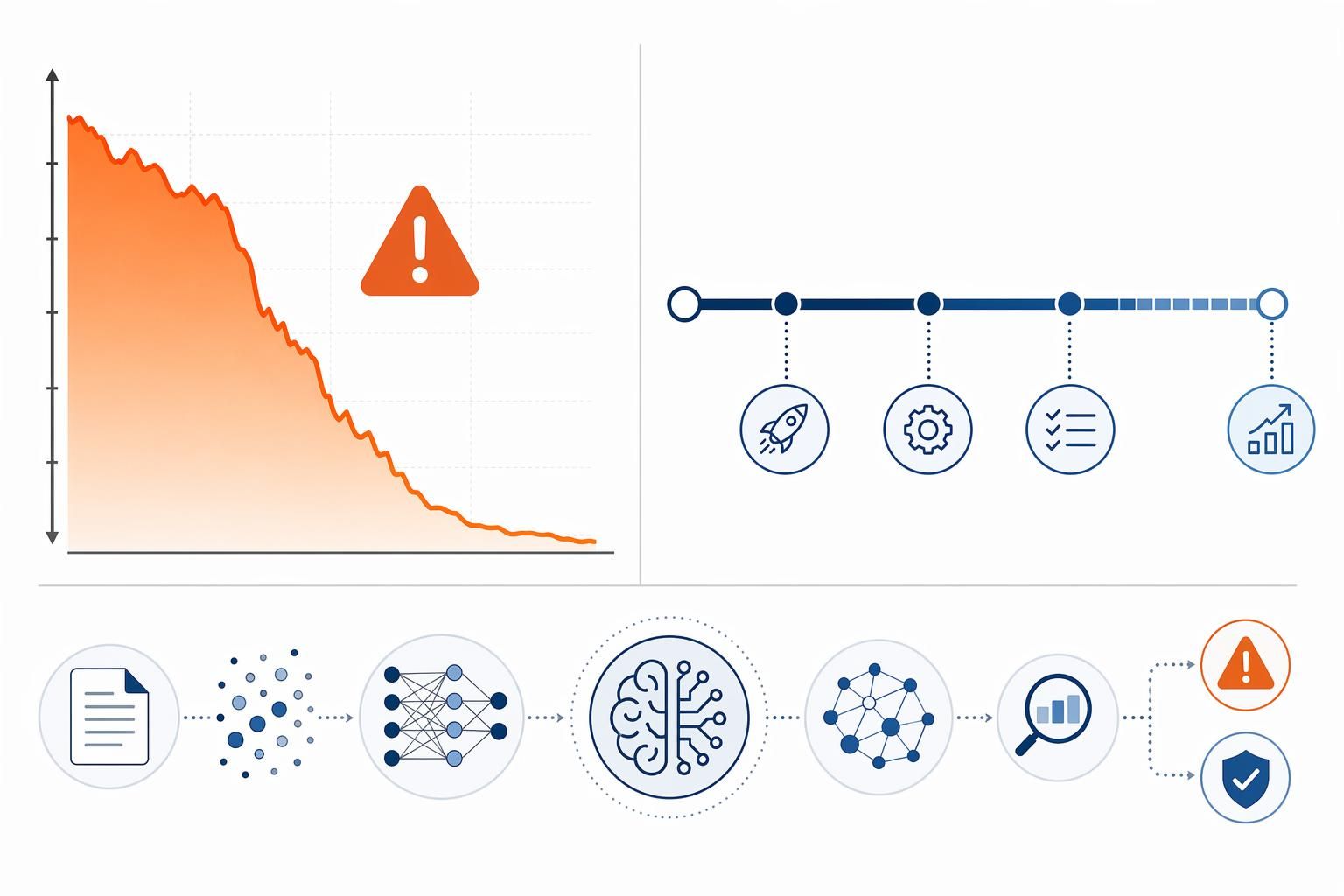
Lao Zhang then spent three months manually rewriting the core article to include real frequency response curve tests and wearable pain point descriptions before the traffic returned to its original 40%.This case is not the end, but the beginning - from March 2024 to February 2026, search engine attitudes toward AI content went through three key turns, each time raising the bar for content access. If you're still running your website with the AI content strategy of 2023, what's coming next may not just be a decline in traffic, but aConfidence-Based Pre-Trial Mechanism (CBPM)The indexing rejection under.
2024 to 2026: Three Turns in Search Engine Attitudes Toward AI Content
Lao Zhang's case is not an isolated one. From September 2023 to February 2026, the search engine's attitude toward AI content completed three critical turns and upgrades. These were not gentle iterations, but three precise policy-targeted blasts, each redrawing the boundaries of the content track's existence.
The first turning point occurs in September 2023: the system recognizes AI content from “can it be found” to “should it be demoted”.
That round of Helpful Content Update (HCU) has left a lot of content webmasters with a lot of heartburn to this day. One small tech blog I was observing at the time saw its traffic evaporate overnight by 601 TP6 T. Google deployed its first large-scale deployment of the ability to recognize AI-generated content and systematically classify it as a low-quality signal in this update. What's more, it launched a beta version of SGE (Search Generative Experience) at the same time - the AI summary box at the top of search results started generating answers directly. These two things happened at the same time, the signal could not be clearer: Google itself with AI directly answer user questions, so as a competitor, those for the sake of ranking low-quality AI content, what is the value of existence? The purpose of the algorithm has changed from helping you “be found” to determining “whether you are worth being found”. From that moment on, the rules of the game of AI content have completely changed.
The second turning point was marked by two updates in March and May 2024: from “identification” to “removal”, the attitude changed from that of an inquisitor to that of a scavenger.
If the September 2023 update was a “warning sign”, then the 2024 move was a “demolition of illegal structures”. 45 days long core update in March, Google publicly announced that its goal was to reduce 40% of low-quality content, which resulted in an actual reduction of 45%. Google publicly announced that its goal was to reduce 40% of low-quality content, but the result was an actual reduction of 45%. Helpful Content, a set of criteria, was integrated into the core ranking algorithm from a separate scoring system. This means that the fight against AI content is no longer an “add-on” but a “must-answer” question that is integrated into every search ranking calculation.
Immediately after that, on May 5, Google launched a special “Fight AI Spam Update”. The official statement of this update is very straightforward, the target of the fight is clearly “mainly for improving search rankings and lack of original value” AI content. This is tantamount to giving the death sentence to a large number of “pseudo-original” AI water army. The algorithm is no longer obsessed with whether your content is “AI-generated”, but rather judges your motivation - “Were you created to cheat my rankings?” It's a fundamental shift in perspective.
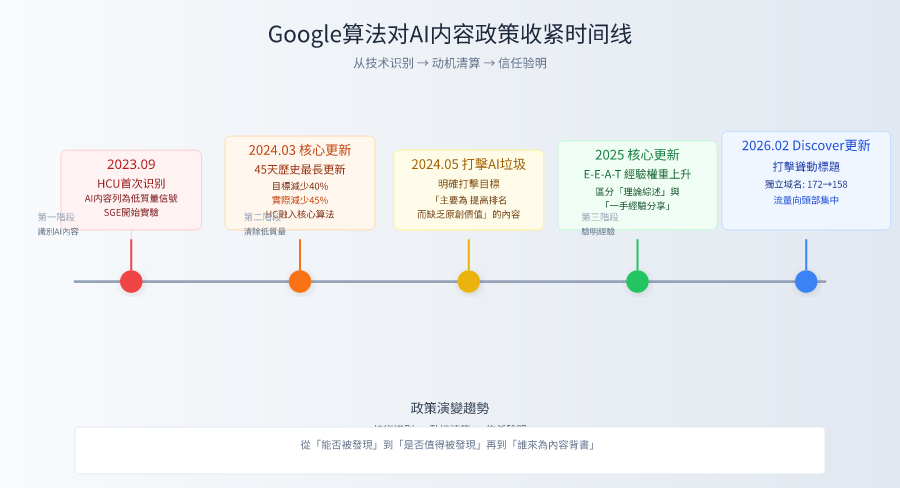
The third turning point, which runs from 2025 to early 2026: from “what content is” to “who it comes from”, trust and experience become hard currency.
After two rounds of cleansing, the remaining AI content “survivors” have been more or less manually touched up. Thus, the core update of 2025 focuses on a deeper question: who will endorse this “touch-up”? The “Experience” dimension of the E-E-A-T principle is given unprecedented weight. Algorithms are beginning to make a fine distinction between “theoretical overviews of something” and “experiences of having done something”. There is a world of difference between an AI-generated article with a few “author's thoughts” added by an editor, and a practitioner-dictated article full of details, errors, and authenticity.
This desire for “first-hand experience” reached new heights with the February 2026 Discover update. This was the first time Google released a core update exclusively for Discover streams, with a precise goal: to combat sensationalized headlines and prioritize in-depth originality. The result? The update saw the US Discover Top 1000 shrink from 172 to 158 unique domains. Traffic was further concentrated toward the headline sites that produce authentic, in-depth, professional content. Algorithms are still closing the door on AI content that lacks depth in a streaming scenario that emphasizes “attraction” more than “retrieval”. This shows that the pursuit of high-quality, high-trust content has become a unified will across all of Google's product lines.
These three transitions are clear: from technology identification (2023), to motivation clearing (2024), to trust verification (2025-2026). Each time is not a minor repair, but a closing of the “loopholes” of the previous round and a raising of the bar again. The story of the Lao Zhangs is the inevitable outcome of this tightening of the net.
So, in 2026, what kind of new rules does Google use to screen out “unqualified” AI content at the indexing stage? This new set of rules is the three core changes that will determine the life and death of your website.
Three core changes to indexing strategy in 2026
If the previous upgrades were “layers”, the three changes that are happening today in 2026 embed the screening mechanism directly into the front end of the indexing process. They are not fixes, they are rebuilds.
Change 1: AI content filtering mechanism upgraded - from “whether it is AI” to “whether it has value”.”
This is the most insidious and deadly step in 2025. Many webmasters are still struggling with the question “Can Google detect that I'm using AI?” without realizing that this question is already outdated.
In the 2025 core update, Google deployed a new detection system that no longer focuses on the AI features of the text, but on the “neurodiversity” of the content itself. The so-called neurodiversity feature is essentially the algorithm's ability to perceive the degree of patterned content - when it finds that an article shows a high degree of algorithmic consistency in its structure, wording, and argumentative logic, it will automatically label it as “low-value patterned content”. label. In short, Google now cares not about what you write, but what you write has “human flavor”.
What does this switch in judgment dimension mean? It means that even if you use the most advanced AI tools, use the most natural tone of voice, or even find native speakers to help you proofread, as long as the content itself lacks a unique cognitive structure and lacks differentiated value that distinguishes it from similar articles, it may be directly filtered at the indexing stage, and it doesn't even have a chance to enter the ranking competition. This is not metaphysics, this is the real reason why a large number of website traffic plummeted after the 2025 algorithm update.
Change 2: Trusted pre-clearance mechanism front-loaded - identification before indexing queues
If change one is a trial of content quality, change two is a review of the identity of content producers.
Beginning in 2025, Google made a fundamental change to its indexing strategy for new pages: the trust pre-review mechanism was front-loaded. In the past, a new piece of content was published and usually found and attempted to be indexed by Google within a few days. Now the process has become: after a new page is submitted, it will first enter a trust assessment queue, and only verified content will enter the official indexing queue.
At the heart of this mechanism is the materialization of the E-E-A-T principle. To put it more bluntly, Google now looks at “whether there is a credible person or organization behind this article that is willing to take responsibility for it”. It recognizes authorship information embedded in the page, such as the scholar's ORCID ID, institutional affiliation, industry credentials, etc., and cross-checks this identity information with known high-authority sources.
A case study that has been widely discussed is the practice of a medical device company in Shanghai. The company embedded co-authors“ ORCID scholar signatures and organizational entity mapping on its professional content pages. The effect was immediate: the average indexing time for new pages plummeted from 17 days to 9 hours. 17 days vs. 9 hours makes Google's attitude clear - it's not penalizing AI content, it's rewarding players who are willing to ”endorse content with their real identities". It is rewarding players who are willing to "endorse content with their real identity".
Change 3: Freshness Factor Weighting Soars - Static Content Depreciates Rapidly
The third change is perhaps the most insidious, as it does not address the quality of the content itself, but rather the “lifecycle” of the content.
In 2025, the weight of the “freshness factor” in Google's algorithm has soared to 35%. This is not a negligible fringe indicator, but one of the core ranking parameters. Its core logic is: content has a “shelf life”, especially those AI-generated content based on data, facts, and time-sensitive information, and if it is not synchronized with the real world after publication, it loses the ability to “solve user problems”.
This directly pronounced the death sentence of “once-and-for-all” AI content strategy. In the past, the kind of AI batch generation of a bunch of “evergreen content” and then let it go, is now facing two fatal problems: First, when similar content in the search engine oversupply, the algorithm will inevitably prioritize the display of the continuously updated version; Second, Google has already had the ability to identify “whether the content is synchronized with the background data”. Whether the content is synchronized with the background data "ability. The price of a product detail page is still the same as when it was published, and the data cited in an article is still the same as last year's or even the year before - all of these details will be captured in the indexing evaluation in 2026.
This means that the workflow of AI content creation must be connected to the data backend, and automatic API interfacing between the CMS and business systems is no longer a “plus” but a “must”. Only content that can synchronize changing data (e.g., pricing, inventory, technical parameters, industry dynamics) in real time will be able to sustain traffic in the post-2026 search environment.
These three changes add up to a complete picture of what AI content indexing strategies will look like in 2026: algorithms will not only be evaluating how well you write, but they will also be verifying who you are, whether you can be trusted, and whether your content is “alive”. This is not alarmist talk, it's happening now.
How are these changes affecting your website? Traffic, rankings, the way it works - I'll put the specific effects into detail in the next chapter.
These changes are affecting your website
These changes aren't technical documents stuck in algorithm announcements, they're reshaping your site's traffic profile in concrete and brutal ways.
The most direct impact from the user behavior data. google now take the page dwell time and bounce rate as a hard indicator of indexing access. Data shows that content with a dwell time of less than 10 seconds has a retention rate of less than 15% on the first page of Google; and once the bounce rate exceeds 65%, the risk of ranking drop will be steeply elevated by 40%.What does this mean? It means that even if your article passed the trust pre-screening, avoided the neural network feature detection, as long as the user clicked in three seconds and left, Google will immediately determine that this is a “not worth indexing“ content. AI-generated patterned content often present this characteristic: title party cheat click, the body of the text is empty and nothing, the user swept the glance and then leave. This kind of content in 2026 indexing strategy, even the chance of being included in the fast shrinking.
The technical performance threshold is likewise being tightened. Mobile loading speeds of less than 3 seconds have become hard indicators, and beyond this threshold, 50% users will leave directly. This is especially tricky for WordPress sites - many webmasters are addicted to AI batch content generation, but ignore image compression, CDN acceleration, redundant script cleanup. When you use AI to generate 50 articles a day, have you ever checked the first screen load time of those pages? In today's content oversupply, technical performance defects will directly trigger the index downgrade, because Google determined that “even the basic user experience can not guarantee the content, do not deserve to get ranked“.
Even more insidious, but deadly, is the spike in the weight of the “experience“ dimension of the E-E-A-T principle. More than 60% of SEO practitioners have observed that demonstrating the author's real experience and industry endorsement has a significant impact on trust. This is not simply a byline, but requires a verifiable professional identity - ORCID scholar ID, industry certification, entity affiliation. pure AI-generated content lacks such “human traces“, and in the context of the pre-qualification mechanism of trust, it faces difficulties in indexing or in the form of a “human footprint“. Pure AI-generated content lacks such "human traces", and in the context of a pre-censored trust mechanism, it is almost a foregone conclusion that it will face indexing difficulties or a steady decline in ranking. I have seen too many cases: website content update frequency has not changed, but the index volume is declining month by month, the root cause is that the algorithm recognizes that these contents "no one is responsible for it".
The impact of the content freshness factor weighting up to 351 TP6T is also showing. Static, one-off generated AI content is depreciating rapidly. If your product page price is still three months old, if your industry analysis quotes last year's statistics, Google will determine that this piece of content is already “dead“. 2026 indexing strategy requires that the content must be kept in a “state of life“! --Synchronize with backend data in real time, and update iteratively. Those who expect to use AI batch generation “evergreen content“ and then let go of the webmaster, is experiencing the pain of the index volume falling off a cliff.
These impacts are not warnings, they are a reality that is happening. Is your indexing dropping? Are you getting slower and slower to include new pages? Are your rankings fluctuating for unknown reasons? If the answer is yes, then you're already at a crossroads where change is needed.
But this is not a desperate situation. Now that we know the rules, we can find a path to compliance. The next question is only one: what should WordPress webmasters do in the face of these implications?
Compliance strategies that are proven to work
Now that Google has made its stance clear, it's time to stop asking “can AI content still be done” - the real question is how exactly are we going to be compliant under the 2026 rules.
The approach is not to fight the algorithm, but to understand the will behind it: Google wants the content to really solve the problem, with real human judgment behind it. Thus, the most effective and repeatedly proven method is to establish a close symbiotic relationship between AI and human, which I call “Cyborg mode”. This is not simply “AI writes, human proofreads”, it is a rigorous three-stage workflow.
Phase 1: AI-generated content skeleton (rough house)
Using AI (e.g. DeepSeek or via theDuck & Pear AI WritingThe first draft is generated on the basis of the instructions (the model accessed by such tools). The purpose of this step is to solve the problem of “failure to write” and “slow writing”, and to quickly build the logical framework and structure of the message. Remember that what you produce at this point is just a “rough house” and you should never push it out into the world.
Phase II: Injection of professional insight by industry experts (reinforced concrete)
Industry experts must step in. Their task is not to change a sick sentence, but to do three things: first, check and correct the accuracy of all technical parameters and statistics; second, based on their own experience in the industry, add insights that AI can't generate out of thin air, for example, “the actual impact of this new policy on the supply chain of small and medium-sized sellers will be a lag”; and third, identify and eliminate vague assertions that are not supported by practice. Third, identify and eliminate vague assertions that lack practical support. This is the core step to shift the content from “information stacking” to “industry solutions”. A foreign trade website service provider strictly implement this process, its content originality score increased by 85%.
Phase 3: UX Designer Refactoring Expression (Finishing)
The last step is for designers or content creators who understand user experience. The core mission is to “de-AI” the content so that it reads like it was written by a human being, or even like an old friend sharing it. This means adding real-life usage scenarios, supplementing stories, adjusting sentence pacing, inserting visual anchors (e.g., charts, comparisons), and ultimately making users want to stay for 3 minutes instead of 10 seconds. After this triple artificial “gold plating”, a piece of AI-driven content with a “human soul” is complete.
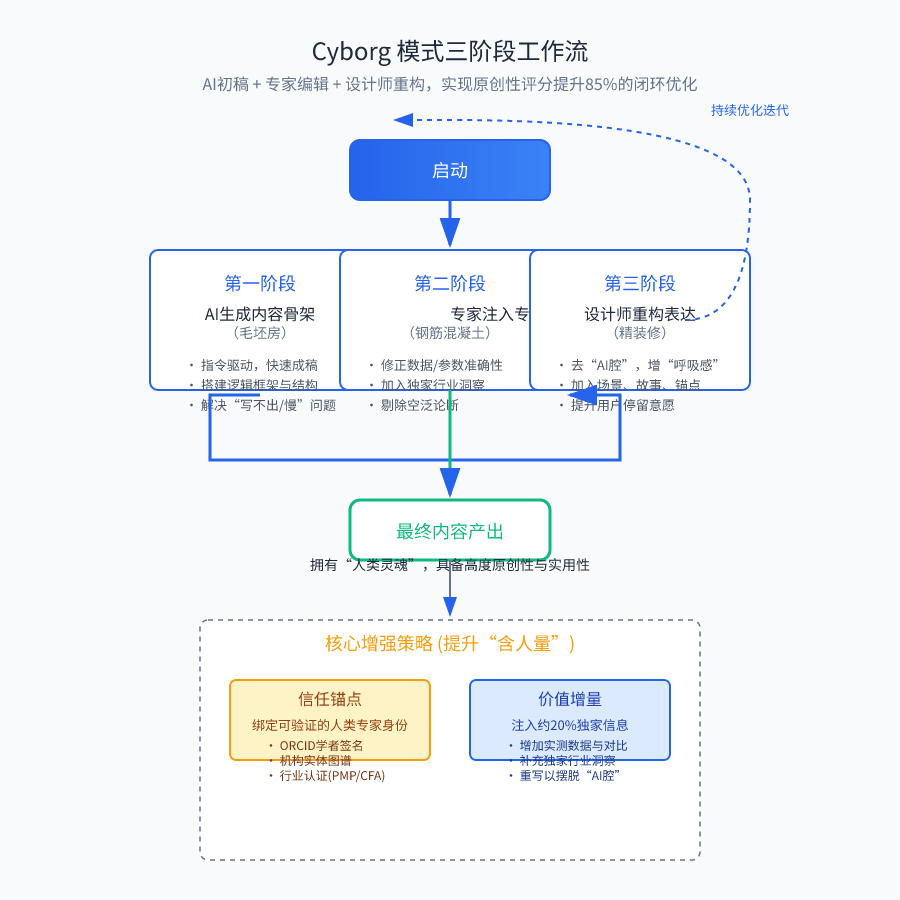
This workflow is effective because it accurately responds to three major changes in the indexing strategy: expert editing corresponds to the “trust pre-screening mechanism”, user experience transformation corresponds to the “user behavior data threshold”, and continuous optimization iteration is associated with the “content freshness factor”. The "Content Freshness Factor".
Next you have to address the issue of trust in your identity. Google's algorithms are becoming more and more like a professional HR that is evaluating your “resume”. A purely AI-generated piece of content is like a blank resume with no references and no work history - it goes straight into the trash. You must tie a verifiable human expert identity to the content.
The most worthwhile way to invest in this is to bind academic and research identities, such as embedding the author's ORCID (Open Researcher and Contributor Identity) ID in the JSON-LD structured data of an article page.The case of a medical device company in Shanghai is very convincing: when they bound the ORCID scholar signatures and the institutional entity mapping to the content in their website, the average indexing time for new pages was reduced from 17 days to 9 hours. This fact reveals the new logic of the search engine: it no longer trusts just “who you say”, but “why you are qualified to say” with verifiable credentials.
For non-academic fields, there are ways to do the same. Showcase specific industry certifications (e.g., PMP, CFA), tie to a company's physical encyclopedia entry, or even link to verifiable, historically active social media accounts in your author bio. These “human traces” act as an authoritative stamp of approval for your content, a passport to bypassing the identity checkpoints in “trust pre-screening.”
But identity alone is not enough. 2026 algorithms have evolved to assess the “human content” of content - that is, what percentage of the content is exclusive information that AI cannot generate. Data suggests that adding about 20% of exclusive information manually can lead to a significant inflection point in rankings.
Where does this 20% come from? It must be the “flesh and blood” that is truly valuable and originates from human practice. I give you four clear directions for collection:
Add real-world data and comparisons.
AI can tell you that “a certain scrubber has a suction power of 18,000Pa”, but if you test it and find that it actually cleans 40% less efficiently on shag carpet, that data is your exclusive asset. Add a graph of your own performance, or a comparison table of actual power consumption with competitors, and the value of this piece of content takes on a completely different dimension.
Add exclusive industry insights.
AI can summarize the news, but it can not tell you “due to the supply chain shift in Southeast Asia, Shenzhen mold factory is experiencing a round of structural price adjustment”. This kind of “water temperature” from the front-line practitioners dinner, industry small circle exchanges, is AI can never touch. Put it in writing.
Rewrite to get rid of the patterned “AI voice”.
Scrutinize the syntax of the first draft of the AI. Are there any stereotypical summaries like “In summary ......” and “Notably ......”? Is there an all-encompassing but unfocused structure? In your own words, rewrite it like a chat from the user's actual confusion. Make the article “breathe”.
Provide directly reusable resources.
AI can write tutorials, but it can't provide a SOP template, Python script, or model contract that has been validated on a real project and that you've debugged by hand without error. By including these resources as attachments or showing core code snippets directly, the usefulness of the content will skyrocket, and user dwell time and sharing rates will naturally rise.
The essence of this “20% rule” is to tell search engines that this content is not copying known information, but creating new solutions based on human experience and practice. This is the core of Helpful Content 2026.
Finally, these strategies don't work in isolation, they need to be integrated into your daily operations. This means that you must leave behind the old habit of “one-click generation, one-click publishing” and establish a systematic process that includes planning, generation, in-depth editing, technical optimization, and continuous updating. This process requires the right tools to lubricate collaboration and lower the execution threshold. For example, how do you efficiently manage such a writing process involving multiple roles? How do you ensure that the quality of the first draft is high enough to minimize the cost of revisions by experts? These are precisely the questions we will focus on in the next phase.
With the right tools, efficiency and quality can go hand in hand
Cyborg mode, expert identity binding, exclusive information injection, these strategies sound right, but many peers told me: “I understand the reasoning, but the operation is too tiring - the selection of topics by hand search, keywords written by experience, the AI tool to change around without a handy, a set of process run down than purely manual labor is still tortuous.”
This is indeed the reality. No matter how good the strategy is, the cost of implementation is too high and people will give up. Instead of recommending specific tools, we should first tell you the underlying logic of choosing tools - so that you at least know what it means to “choose the right one”, rather than being led by the hand.
Tool screening logic for 2026
Google and Baidu's attitude towards AI-generated content has changed from “can you use it” to “how do you use it”. The two recognition mechanisms are different, resulting in different emphasis on the selection of tools.
Google's indexing strategy, which I dismantled in the last chapter, has a core logic of **“human content”--You have to show that there is real experience and judgment behind the content. So the right tool saves you the physical labor of a first draft; the wrong tool generates the perfect crap that becomes a trust liability instead.
Baidu's thinking is not the same. It requires a higher degree of real-time and Chinese semantic granularity, and the 2026 “AI-assisted content” judgment relies more onIntent recognition和Entity associated**. This means that in the Baidu side, your tool can help you implant exclusive data, supply chain frontline observation such as “Baidu encyclopedia does not have things”, more important than the writing itself.
Based on these two sets of logic, I'll give you three screening dimensions:
First, see if the tool supports a phased intervention. The real Cyborg model is not to let the AI write it all in one go, but to allow you to mobilize the tool's capabilities in each of the three phases: “Skeleton Generation”, “Expert Involvement”, and “De-AIing”. Instead, it allows you to mobilize the tool's capabilities in each of the three stages of “skeleton generation,” "expert intervention," and "AI removal. Those tools that claim to be "one-click to generate a hit" are probably not suitable for this workflow.
Second, see if the tool's SEO capabilities are localized enough. Here is not talking about the home page keyword density, but long-tail word expansion, semantic vector optimization, GSC data back to these underlying capabilities. Baidu especially eat this set - if you find that a tool can only give you a set of keywords, but can not give the semantic coordinates of these words in the entire content matrix, then its SEO value to put a question mark.
Third, look at the tool's ability to “de-AI”. It's a direct decision on whether your content will die before the indexing threshold in 2026. There's no tool that can replace manual labor for this step, but it can help you do a first pass - flagging up those patterned expressions like “in summary” and “notably” - so your editor knows where to start. and let your editor know where to start.
Putting these three dimensions together to evaluate the mainstream AI writing tools on the market, you will find that most of them have a clear functional bias - some are strong in topic selection, some are strong in batch generation, and some are strong in SEO optimization. The ones that can really cover the three dimensions in full, I use them to feel thatDuck & Pear AI WritingIt is one of the smoothest integration of “AI efficiency” and “manual gatekeeping” at present. Its intelligent theme engine can help you from keyword association, competitor analysis, hotspot capture multiple perspectives batch output executable selection, dual-track writing mode can be matched with standard batch generation and deep manual collaboration scenarios, built-in SEO tool chain and rewrite and embellish the function can also support the first round of operation “to AI cavity”.
But I will say this: tools are just lubricants, not engines. What you should really take the time to do is solidify the Cyborg model into your daily routine. My suggestion is: let the tool help you run out of the topic selection stage with keyword suggestions in the topic library; use the tool to quickly come up with the skeleton in the first draft stage; use the SEO tool to check the keyword density and semantic completeness during the manual editing stage, and at the same time, use the rewrite and embellish function to do the first round of “going to the AI cavity”; and finally, use the data insights to continuously track the performance of the content.
Once this process is running smoothly, the tools can really help you combine efficiency and quality.
2026 Action List for WordPress Webmasters
Earlier we talked about how the Duck & Pear AI writing tool is embedded in the Cyborg model, but the tool is just a weapon, and the battle has to be fought on tactics.The AI content indexing strategy for 2026 has tightened up, theConfidence-Based Pre-Trial Mechanism (CBPM)和Neural Network Feature DetectionIt's running, your site may have been flagged just haven't received the notification yet.
Don't wait, this list is a list of actions you must accomplish in the next 48 hours.
Step 1: Skinning the stock content
Open your WordPress backend and go through the AI-assisted content published in the last 6 months, article by article. Each post must be tied to a verifiable human identity - not just a random “Zhang San“, but an academic profile with an ORCID link, an industry expert with a LinkedIn endorsement, or an organizational identity with an institutional entity mapping. Without author information, the algorithm defaults to machine spam.
Path: Article editing page → Author information field → Add external identity link → Update site structured data.
Step 2: Soldering Cyborg Mode into the Workflow
As of today, direct publication of first drafts of AI is prohibited. CreateHuman-computer collaborative workflowThe three gates: duck pear AI's standard model out of the first draft (first stage) → industry experts injected with real-world data and exclusive insights (second stage, must contain 20% artificial exclusive information) → remove the AI cavity with a deep model or manual rewrite (third stage). Each gate should have a clear responsible person and delivery criteria.
Step 3: Technical Performance Life and Death Line
Open Google PageSpeed Insights and test your 10 most trafficked pages. For mobile load speeds higher than 3 seconds, rectify the situation immediately: compress images to less than 100KB (in WebP format), remove rendering-blocking JS, and enable a CDN.Remember, the 2026 indexing strategy has a 40% elevated risk of page rank drop for pages with a bounce rate higher than 65%, and load timeouts are the number one killer of bounce rates.
Step 4: API your content
Static AI content is failing because theContent freshness factorThe weight has been raised to 35%. Check if your CMS has access to backend data APIs: e-commerce sites need real-time inventory and price synchronization, tech blogs need real-time parameter updates, and news sites need automatic refreshing of posting timestamps. WordPress users can interface to the internal system with the WP REST API to ensure that pages are automatically updated when key data changes.
Step 5: Content Genetic Modification
For pages that are already ranked but are experiencing a drop in traffic, perform a manual in-depth remodel: add real-world data (scores, power consumption curves), add exclusive insights such as supply chain, rewrite the opening 300 words to remove AI accent templates such as “in today's digital age,“ and add a library of downloadable SOP templates or scripted conversations. The goal is to makeThe E-E-A-T principleThe “experience“ dimension is visible to the naked eye.
Complete these five steps before your site gets immunity from the AI content siege of 2026. The price of delay is a permanent backseat in the indexing queue - the search engines won't alert you to this, it'll just send your traffic to zero in 47 days.
Now get to it.