
You may not realize it: you're exposed to AI-written text every day
The summary of hot news you swipe in the morning, the weed notes you browse on your lunch break, the product detail page you see after work, or even the emotional tree-hole you swipe into late at night - how much of that text was knocked down by a real person?Today in 2026, the answer may make you uncomfortable: content generated by big language models has infiltrated the information like tap water pipeline, and you're often unaware of it.

This is not alarmist talk. From ChatGPT to specialized tools like Duck Pear AI Writing (https://www.yaliai.com/), AI is producing text at a rate of millions of words per minute. The explosive copy on e-commerce platforms may be batch generated by AI; the financial blogger you follow may be using the tool to change ten articles a day; even the acknowledgement section of academic papers is starting to see controversy over machine ghostwriters. When you think you are talking to a living person, the opposite side may just be a string of probability calculations; when you are impressed by a “deep good article“, the author may never exist. This infiltration is so insidious that the official detector launched by OpenAI in 2023 could only recognize AI texts of 26%, and was eventually forced to withdraw due to poor results - even the people who created the AI had trouble distinguishing their own creations.
This leads us to a sharp technical proposition: AI text detection. It sounds like a cold subject in the lab, but is essentially a brutal binary classification problem - determining whether a piece of text came from human flesh and blood or from the probabilistic predictions of a silicon-based algorithm. There is no middle ground, no gray buffer, just a yes or no determination.
You may ask: why the distinction? Because the credibility of digital content is collapsing. When AI can perfectly mimic anyone's writing style, when machine-generated “experience sharing“ is smoother and more seamless than that of a real person, we need a line of defense: AI text detection is not a technological toy to be added to the mix, but rather an infrastructure that maintains the information ecosystem - it determines which content is trustworthy and which “real life stories“ are mere illusions. It determines which content is trustworthy and which "real-life stories" are just algorithmic illusions. Behind this line of defense lies a statistical fingerprint that big language models can't erase.
Why AI is caught by the tail
But why does even OpenAI's own detector fail? Why is it that a company that creates AI is instead unable to accurately identify its own most successful products? It's not a technical failure, it's an intrinsic dilemma - and it stems from the core identity of the big language model: the probabilistic predictor.
Imagine you're writing a work email. Write the first three words “about on” and your brain will instantly conjure up a dozen possible follow-up words - “weekly, sub, weekly meeting, quarterly report”. You'll choose “weekly meeting” based on context, purpose, or even emotion. A big language model does essentially the same thing, except that its “brain” is a probabilistic network trained with trillions of text fragments.
When you give an AI the beginning “Spring morning”, the first thing it does is query its neural network: out of all the text it has seen, what word has the highest probability of appearing next? It might calculate: “sunshine” with a probability of 38%, “breeze” with a probability of 22%, and “air” with a probability of 15%! In order to generate smooth sentences, ...... will tend to choose words at the top of the probability distribution - for example, “sunshine”. So the model writes “The spring sun shines brightly on the windowsill”. Then it goes on: what could be after the windowsill? The network calculates again: “up” with probability 45%, “side” with probability 18% ...... “up”. ". And so on and so forth.
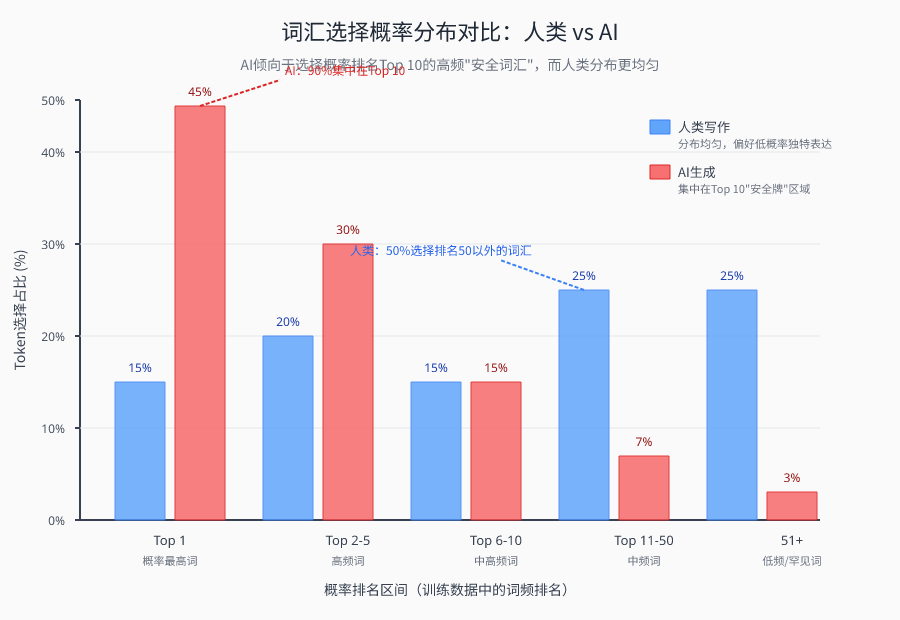
This mechanism is the first fingerprint of AI texts: the “conservatism” of word choice.
Because the model must generate semantically fluent text, it instinctively chooses the most common and sensible combination of words in the training data. This is not a mistake, but an inevitable consequence of design. It's as if a chef will only pair ingredients from the few he or she is most familiar with, and will never risk trying strange combinations they've never seen before. So AI-generated text is naturally limited in vocabulary diversity - it has almost no true “out-of-the-way” words, and every word is a safe card in a probability game.
However human writing is completely different.
When you write “spring morning,” you may suddenly want to use “morning sun” instead of “morning,” or “pouring” to describe the light. “to describe the light. These choices may not seem very probable to a big language model - because in the training data, the pairing of ”morning sunlight pouring down“ is indeed less common than ”sunny“. But this ”low probability" is a reflection of human creativity: we go beyond the most sensible combinations to pursue expressive uniqueness, emotional color, or even just personal preferences.
Human writing has moments of randomness. You might suddenly insert a colloquial “to the end” in the middle of a rigorous argument, or create a pause with a dash - these “imperfect” syntactic structures don't occur as often in AI text. AI sentences are always grammatically complete, structurally standardized, and have smooth transitions because its neural network learns the most grammatically correct patterns, but cannot understand why humans sometimes break grammar on purpose.
Look again at paragraph articulation.
The human mind is jumpy. At the end of a paragraph, you may be interrupted for a few seconds by birdsong outside your window, and then start the next paragraph with new inspiration. Such interruptions leave traces - the transitions between paragraphs may be slightly hard, and the logical turns may not be natural. But the AI has no such “distractions”. Its neural network maintains semantic consistency throughout, smoothly transitioning from one topic to another, with each sentence acting as a perfect sequel to the previous one.
This excessive smoothness is another fingerprint. Read a piece of AI-generated text and you'll feel as smooth as if you're gliding along on a track with no bumps. Real human writing, on the other hand, will give you a little surprise somewhere-an abrupt but powerful metaphor, a sharp turn in logic, a clumsy but honest attempt. These “bumps” are proof of the human condition.
Why is it important to understand these fingerprints? Because they form the core foundation of AI text detection. All detection tools-whether it's GLTR, which is based on probability ranking, or classifiers that analyze text entropy and perplexity-are ultimately looking for these statistical features: overly-perfect lexical distributions, overly-standard syntactic structures, overly-smooth semantic transitions.
But there's a deeper contradiction buried here: if AI-generated mechanisms inherently leave fingerprints, why is detection still so difficult? Why do OpenAI's detectors fail? Because big language models are evolving rapidly and these fingerprints are being faded.
The larger the model, and the richer the training data, the more low-probability plausible combinations it can generate. In 2026, the latest generation of big language models will have learned to mimic human imperfections - it will deliberately insert seemingly random modifications into sentences, and it will make paragraph transitions a bit artificially stiff. Just as counterfeiters are learning how to add deliberate imperfections to their fakes.
This creates an ongoing game. Detection tools chase statistical features of AI texts, while AI models learn how to erase them. As you'll see in the next chapter: while GLTR tries to catch the AI by the tail with probability rankings, the big language models are already learning how to make their probability distributions more human-like.
Pandora's Box opened by GLTR
You may have noticed that the previous chapter revealed the statistical fingerprints of AI text-the conservatism of lexical choices, the overly standardized syntactic structure, the unusually smooth paragraph transitions. But it's one thing to know that fingerprints exist; it's another to actually turn them into actionable detection tools.
In 2019, researchers at MIT and Harvard University developed a tool called GLTR, the full name of which is “A Giant Language Model Test Room“ - a room dedicated to testing large language Model Texts. The advent of this tool has, for the first time, turned abstract probability theory into a testing tool that can be used by ordinary people.
So how does GLTR work?
Recall the nature of a big language model: it generates each word (token) by calculating the probability of all possible candidates and then tends to choose the one with the highest probability.The clever thing about GLTR is that it invites a “referee” big language model to analyze the input text word by word. For each token in the text, the referee model calculates its probability ranking among all words. If the token is ranked very high (e.g., in the top 10), it is a “high-probability safe token”-typical AI behavior. If the rankings are spread out, it means that the writer is experimenting with more diverse vocabulary choices.
This is the first core metric of GLTR: token probability ranking.
The researchers did an intuitive visualization: marking the rankings of each token in the text with a color. the AI-generated text, almost every word flashed the same color - they were all crowded at the very top of the probability rankings, like a group of regular soldiers. Human-written text, on the other hand, is colorful - some words are at the top, some are in the middle, and some may be very far back. This probability distribution is the “heat map fingerprint” of the AI text.
But there is a technical detail here: there is a problem with using the absolute probability value of token directly. If an out-of-the-way word suddenly appears in an article, it may have an extremely low probability of being ranked 50,000th, an extreme value that can seriously distort the overall assessment. So the researchers introduced log rank - taking logarithms of the rankings. This mathematical trick “compresses” the extreme rankings back into a reasonable range, making the assessment more robust.
After the technical principles, how does it work in practice?
The researchers designed a comparison experiment: untrained subjects were asked to determine which texts were AI-generated and which were human-written based on intuition alone. The result was an accuracy of only 54% - almost equal to a random guess. This suggests that it is difficult for humans to detect subtle features of AI texts with the naked eye alone.
But when these subjects retested the same batch of text with the help of the GLTR visualization tool, the accuracy jumped to 72%.
A tool that delivers an 18-percentage-point improvement is quite substantial.72% What does it mean? It means that in three judgments, the tool correctly recognizes AI-generated text twice. This number is far from perfect, but it's enough to make GLTR a milestone in the field of AI text detection - it proves that statistical methods can indeed capture patterns that are hard to spot with the human eye.
The success of GLTR verifies the feasibility of “probabilistic fingerprinting”, but the context of its time is also worth noting. It was 2019, GPT-2 had just been introduced, and AI-generated content was still in a relatively “rough” stage. With the leap in large language modeling capabilities, these early detectors are facing a serious test: when AI learns to imitate human “imperfections”, what can be measured by the ruler of probability ranking?
This question will lead to deeper thinking.
More than just probability ranking: three paths to mainstream detection technologies
GLTR proved that it is possible to capture AI's statistical fingerprints without training a model, and this TRAINING-FREE idea opened up the first path for detection technology. But when you actually want to build a reliable detection system, you realize that token probability ranking alone is not enough. Over the past five years, researchers have actually opened up three very different technical routes, which are like three searchlights in different directions, trying to illuminate the hidden corners of AI text.
The first path continues the training-free spirit of GLTR, but extends the observation window from the probability ranking of a single token to the statistical characteristics of the entire text. You can think of this approach as a “text physical examination“ - do not disassemble the machine to see the internal structure, but only through the external “vital signs“ to determine the state of health. Confusion is one of the core indicators, measuring how “surprised“ the language model is when it sees the text. If a text does not surprise the model (low perplexity), it is too consistent with the model's predictive habits and is most likely AI-generated; if the model is often surprised (high perplexity), it is more likely to be human-authored. Suddenness, on the other hand, is like detecting “heart rate irregularities“ in a text - human writing has natural ebbs and flows, sometimes concise and sometimes complex, with fluctuating vocabulary choices like an electrocardiogram; whereas AI tends to act like a flat heart rate line in order to maintain a steady output, lacking that breathless rhythmic change. like changes in rhythm. The advantage of this type of approach is that it works out of the box, and there is no need to know in advance which AI model is generating the text; however, the cost is that it is easily bypassed by “rewriting attacks“ - all it takes is for a human being to slightly embellish the content generated by the AI, and to disrupt the overly regular statistical features, and the detector could be blinded. The detector can be blinded.
The second path is a completely different way of thinking: instead of detecting after the fact, mark it beforehand. This is like watermarking every bill generated by AI with a watermark that is invisible to the naked eye. Watermarking-based techniques require big language models to embed invisible signatures at the statistical level by biased selection of specific words or adjustments to sentence structure when generating text. Such markings have no effect on human reading, but specialized decoding algorithms can extract these statistical anomalies from the text to determine the source. Theoretically this is the most elegant solution - detection accuracy can be close to perfect and cannot be eliminated by simple rewriting. The problem is its “exclusivity“: the watermark can only recognize the specific model in which it is embedded, and if you change to another AI tool, or if someone rewrites the text slightly, the watermark will fail. A more realistic problem is that this requires AI service providers to take the initiative to cooperate in the model of the underlying implanted marking mechanism, and not all vendors are willing to open the back door.
The third path goes to the other extreme: using AI to detect AI. neural-network-based end-to-end detection falls under the training-base approach, which ditches explicit definitions of statistical rules in favor of letting the neural network learn to distinguish subtle differences between humans and AI on its own. The researchers collect vast amounts of human writing and AI-generated text to train a specialized classifier. This process allows the model to automatically discover deep features that are difficult for humans to articulate-maybe a particular combination of syntactic structures or an invisible pattern of semantic coherence. This approach can theoretically capture the slightest trace of forgery, but the price is heavy: it requires expensive training resources and faces serious OOD (Out Of Distribution) problems. When a new version of GPT is released, or a completely different model architecture is switched, the previously trained detectors may fail instantly, like using the same neural network that recognizes cats and dogs to recognize birds.
At the intersection of these three routes, a number of well known tools have been created, and the open source version of GPTZero uses the idea of confusion detection, where a “referee“ model of a large language is used to calculate the fluency of the text. But there's a subtle catch: the results are highly dependent on your choice of referee model. If you use GPT-2 to detect text generated by GPT-4, you may get a completely wrong perplexity reading - because GPT-4“s expression is out of GPT-2“s predictive conventions, and will appear "perplexed" instead, causing you to misjudge it as as human writing. This sensitivity to the choice of referee model exposes the fundamental fragility of the training-free approach.
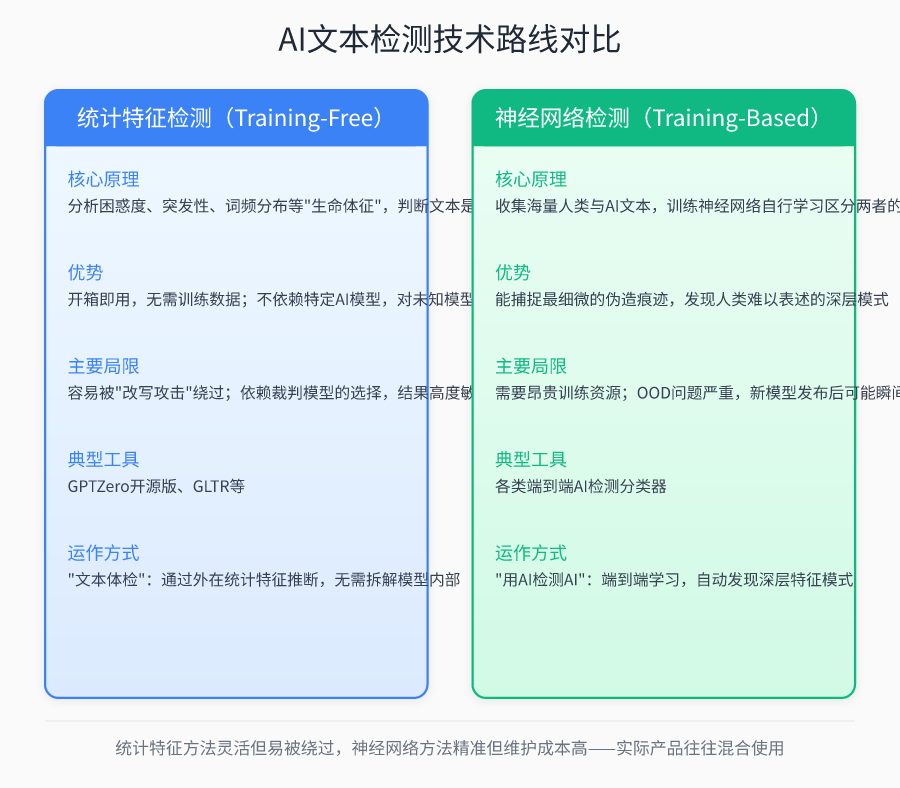
These three paths are not mutually exclusive. Mature detection products on the market are often hybrids - they may use watermarking techniques for initial screening, statistical features to calculate confidence, and neural networks to handle borderline cases. But no matter how the technologies are combined, they all face the same tortured question: how wide is the moat of these detection tools as AI generation capabilities continue to evolve? In the next chapter, we will tear open the beautiful theoretical veil of the technology and see what kind of cruel truth the data in the real world will tell you.
The ideal is rich, the reality is pitiful.
These elegant-sounding technical lines may shine brightly on the perfect data set in the lab. But when you put them into the real world - in the face of jagged texts on the web, stylistic differences in human authorship, and cunning hybrid rewrites - they become instantly wobbly. The ideals of technology are like precise drawings, while the reality is a chaotic construction site.
The most ironic first strike came from the pioneers of the field themselves.In early 2023, OpenAI, the company that single-handedly spawned the era of big language modeling, unveiled its own AI detector. Outsiders expected it to recognize its own products with the precision of a scalpel. However, the real test results were shocking: this tool with high expectations could only capture 26% of AI-generated text. Worse, it would mischaracterize 9% of human writing as AI work. It's like a car manufacturer that can only recognize a quarter of its own brand of cars on the road, and misidentifies many others as its own. Six months later, the detector was quietly withdrawn because it was “not reliable enough”. This cast a long shadow over the entire industry: if even the parents, who know the insides best, can't recognize their own children, what can outsiders expect?
If you see this as a win for open source modeling, you'd be wrong. Appen, an independent data science company, conducted a benchmark test that was more systematic and closer to real-life scenarios. They assembled a team of human and professional writers and used AI tools to create a total of over 600 content samples. In this well-designed laboratory, they conducted a blind test of the major AI detection tools on the market.
The results were cold and consistent: none of the tools reached the 95% accuracy benchmark that the industry generally expects. All detectors performed like myopic coin guessers, with false positives (meaning misclassifying human text as AI) swinging dramatically between 16% and 70%. What does a tool with a 70% false alarm rate mean? For every 10 human-written essays, it would mark 7 of them as “AI cheating”. Imagine how many people's efforts and reputations would be easily wiped out if a student's essay, a journalist's report, or a writer's manuscript were reviewed by such a system. This is no longer a technical flaw, it is a dangerous product that can cause real harm.
After rigorous blind testing of more than 600 mixed human- and AI-generated samples, we found that none of the mainstream detection tools reached the industry-expected 95% accuracy benchmark, and the false-positive rates of all products fluctuated dramatically between 16% and 70%. This means that in the most extreme cases, more than two-thirds of human-originated works are incorrectly determined to be machine-generated.
-- Appen AI Detector Benchmarking Report
Faced with such a high risk of false positives, a natural idea would be to raise the detection threshold, rather than miss than miss. appen's team did this experiment - they tightened the criteria to require that the false positive rate must be lower than OpenAI's withdrawal detector's 9%. under this conservative model of “ better to miss a thousand than to miss one”, what was the best performing GPTZero document-level classifier's true positive rate (meaning the percentage of correctly recognized AI text)? Under this conservative model of "better to miss a thousand than to kill one", what is the true positive rate (the percentage of AI text that is correctly recognized) of the best performing GPTZero document-level classifier?
The answer is: only 131 TP6T.
In other words, in order to avoid injuring humans by mistake, the detector has become so conservative that it is almost “blind” to AI text, and 87% of AI-generated content can slip through its nose. This reveals a fundamental dilemma for AI detection technology: there is a brutal trade-off between true positives (catching AI) and false positives (injuring humans by mistake), and you can't improve one at the expense of the other. You can't have both a highly accurate demon-spotting mirror and a safety lock on innocents who won't be mistakenly injured.
So where specifically do detector weaknesses lurk beneath these macro data? The technical blind spots mentioned in the previous chapter are brutally verified in real data.
First, word count has become the “Achilles heel” of detection. For short texts - a tweet, a comment, a summary, anything under 300 characters - the accuracy of mainstream detectors falls off a cliff. The statistical fingerprint of a large language model needs a certain text length to be fully visible, just as a forensic scientist needs a large enough sampling area to extract reliable DNA. in short texts, the weak statistical anomalies are completely drowned out by the background noise, and the detector can only rely on guessing.
Even trickier is mixed text. In the real world, few people paste AI-generated content as is. More often, AI generates a first draft, then tweaks the tone, replaces words, reorganizes paragraphs, and injects a personal point of view. This half human, half AI “hybrid” text is a nightmare for detectors. Methods based on statistical features will be rewritten to disrupt the rhythm; watermarking-based techniques will be invalidated because of vocabulary replacement; and the neural network detector in the face of this rarely occurring “intermediate state” in the training data set, its judgment is almost unpredictable. What you get is a random, meaningless confidence score.
It's like trying to find a gold coin with a metal detector on a road that has both buried nails and scattered mineral water. There's too much interference, the signal is too weak, and the limitations of the tool are exposed. So the next time you see a detection tool asserting “99% AI generated” or “100% human created”, you need to be immediately wary: it's probably using an oversimplified model to measure an extremely complex and ambiguous reality. It's probably using an oversimplified model to measure an extremely complex and ambiguous reality.
The aura of technology fades in the face of data, leaving behind a truth riddled with cracks. What is it, exactly, that we blindly trust when the reliability of the tool is so dubious? In the next chapter, we'll walk deeper into those cracks and see why, in principle, AI detection is a climb that's destined to be difficult.
Why is AI detection so difficult
The previous section has demonstrated the awkward status quo facing current detectors - high false positives, low accuracy, and the dreaded trade-off dilemma. But these problems are not accidental; they are deeply rooted in the structural contradictions of this technology game.
The model evolves much faster than the iteration cycle of the detector. With each generation, big language models are becoming more fluent, more logical, and more human-like. In the early days, GPT-2 generated text that was still distinctly “machine-like” - monotonous sentences and deliberate wording. But today's GPT-4, Claude, has been able to write text that is virtually unrecognizable on a linguistic level. This means that the “AI fingerprints” that detectors have worked so hard to build are rapidly becoming obsolete. Last year's detector may not recognize the work of the new model this year. It's not that the detector isn't working hard enough, it's that the competition is running too fast.
More importantly.Detectors are naturally characterized by the twin flaws of targeting and vulnerability. The vast majority of training-base based detectors need to be trained with text generated by a specific model before they can recognize that model's work. In other words, a detector trained for GPT-4 may fail completely against Claude-generated text, and even more so against a newly released open-source model. It's like a key that only opens one lock, and the locksmith is still changing the locks.
The diversity of human writing is another underrated conundrum. Also “written by humans”, a law professor's thesis, a post by a post-00s netizen, and a self-media blogger's grass-raising copy, their vocabulary choices, syntactic structures, information densities, and stylistic rhythms are very different. It is difficult for the detector to cover such huge differences with a set of standards. What's even trickier is that a significant percentage of human authors are themselves fluent and logical, and their natural expressions may be highly similar to low-quality AI texts in terms of statistical features - but that doesn't mean the latter are the former.
The labeling dilemma for training data is much more insidious. In a real-world setting, it is difficult to determine whether a text was actually created using AI tools. A student uses AI to polish his or her essay, is it an “AI text” or a “human text”? What about a press release where a journalist uses AI to assist in interviewing and generating the first draft? This ambiguity makes it extremely difficult to obtain high-quality training data, and more often than not, the detector is trained on a dataset with unclear boundaries and questionable labels, which naturally makes it difficult to guarantee the results.
The field as a whole also faces a more fundamental problem: there are no standardized metrics. Different research teams use different datasets, different thresholds, and different evaluation indexes, and their “accuracy rates” are not directly comparable at all. Some papers say the accuracy rate reaches 98%, while others say it is only 60%. The difference may not lie in the superiority of the methodology, but in the fact that they measure different things. Without recognized benchmarks, the so-called “technological advances” may be self-serving.
Does this mean that detection technology is hopeless? Not exactly. What needs to be explored next is what else we can do while recognizing these inherent flaws.
What you need to know when faced with AI writing
Since detectors naturally carry structural flaws, you shouldn't use them as the final judge. Tools that claim an accuracy of 98% tend to hold up only on specific datasets; once confronted with the complexity of real-world text, thefalse positive ratecould soar to 70%.true positive ratecould fall as low as 131 TP6T.OpenAI's own detector captured only 261 TP6T of AI text, which was eventually withdrawn after six months-if it even built themacrolanguage modelof developers can't accurately identify the output of their own products, who are you to trust the singular judgment of some third-party app?
Step 1: Establish the habit of cross-validation.
For any important content, don't open a testing site and jump to conclusions. Try a combination of different technical paths: use a website based on theperplexity和sudden的training-freeTools (e.g. GLTR) to observetokenWhether the probability distribution is overly concentrated; reusetraining-baseIf the two conclusions conflict, or both show “doubtful“, it is time to introduce human judgment - checking the text for logical jumps and details of personal experience. If the two conclusions conflict, or both show "doubtful," then human judgment is introduced - checking the text for logical leaps, details of personal experience, and non-mainstream views in a particular area. The insight of the truly unexpected.
- Simultaneous use of at least two detection tools with different principles (e.g., GLTR based on probabilistic analysis and AI detection tools based on classifiers)
- Observe the token probability distribution graph of the Confusion Degree tool and check if the high probability words are concentrated in the top rows.
- Manual review of the text to check for obvious logical jumps or hard transitions
- Look for whether the text contains specific, unique personal experiences or emotional details
- Watch for non-mainstream, counter-intuitive and unique perspectives in a particular field that appear in the text
- If the results are conflicting or both are “doubtful”, mark them as requiring focused attention and do not rely on a single tool to make conclusions
- For short texts (less than 300 characters) or mixed texts that have obviously been rewritten, the uncertainty of the default detection results is extremely high
- Intervene proactively in AI-assisted writing to inject personalized expression or break out of conventional sentences into the generated text
- Decide whether you need to introduce a more in-depth, peer-reviewed level of manual review, taking into account the importance of the final content
Step 2: Understand limitations and stay humble.
When you know that current detection technologies are almost invulnerable to short texts (less than 300 characters), and that the accuracy of mixed text (manually rewritten AI-generated content) has plummeted, you don't easily label someone as a “cheater“. Conversely, when a paper “passes“ all the tests, you're not naive enough to think it's absolutely innocent - it could just be that a newer model was used, or that it's been cleverly touched up.AI Text DetectionNever the end of truth, but the beginning of doubt.
Step 3: Let perception translate into creative advantage.
As a content creator, it's important to understand thesetext entropyand knowledge of probability distributions, not to avoid detection, but to collaborate smarter. When you useDuck & Pear AI Writing(https://www.yaliai.com/) when it comes to tools like this, understand that itmacrolanguage modelessentiallytokenThe probability predictor will know that it tends to choose statistically “safe“ high-probability words. This is where you can intervene: deliberately inserting personal expressions, breaking the standard sentence structure, adding non-linear leaps of thought on top of the AI-generated ones - these are precisely the “imperfect“ features of human writing, and the key signals that the current detector is looking for. These are the "imperfect" features of human writing and the key signals that current detectors are looking for.
Duck & Pear's AI writing “depth mode“ supports this kind of workflow while writing and adjusting, so that you can enjoy the efficiency of AI while retaining the “human flavor“ that makes the text warm. Remember, the value of tools lies in expanding the boundaries of your ability, not replacing your judgment.
🔑 criticalThe point of the detector is not to give “absolute answers“, but to provide “reference coordinates“ - it measures only probability, and can never replace your thinking and judgment of the content itself. judgment of the content itself.
When we let go of our obsession with technological perfection, we can instead navigate the gray areas of human-computer collaboration with more clarity. Detectors are crutches, but it's always your own thinking that can get you farther.
put at the end
You have traveled this complete journey on AI detection. From everyday encounters with AI-generated text, to the Pandora's Box opened by GLTR, to the attempts and limitations of the three technology paths. You've also seen the bone-chilling realities: the fate of OpenAI detector retractions, GPTZero's inability to control false positives, and its catch-22 in the face of short text and mixed text.
This is a race of speed. Each iteration of the big language model is trying to erase the “fingerprints” of the probability distribution and bring the text closer to the unpredictability of humans. Detection techniques are also in hot pursuit, from simple confusion analysis to complex classifiers that combine semantics and syntax. It's an evolving game, with no finish line to catch up with. Any detector that claims to be “accurate” today can be easily bypassed by tomorrow's models. The technology itself is never stable; the only thing it can give you is an honest measure of the boundaries of what it can do in the moment.
So, instead of getting caught up in the infinite desire for “absolutely accurate detection”, we need to make a fundamental shift in mindset. A tool is a tool, an assistive wheel that helps you eliminate some of the noise of the probabilistic world and focuses you on the truly valuable signals.critical thinking和Content recognitionIt's the hard currency of the age. It's no longer just a question of “Did an AI write this?” It's more about, “Is this argument supported by logic?” “Is this fact validated by data?” “Is there a unique perspective behind this insight?” Whether the text comes from a human or a machine, you should scrutinize it with the same standards.
Ultimately, this quest isn't about making you an expert at recognizing AI, but about making you a more conscious receiver, and a more responsible content creator, in an information environment where AI is everywhere. You can use a tool like Duck Pear AI Writing like a paintbrush, using it to batch-produce drafts and inspire, but leaving the final colors, strokes, and emotions to uniquely human thoughts and temperatures.
🔗 Related resources: Duck & Pear AI Writing
A new generation of intelligent writing system designed specifically for content creators, helping to efficiently produce high-quality original content
Put tools back in their place and let thinking sit firmly at the center.