
收录波动背后藏着什么信号
昨天还收录的页面今天消失了,或者今天新增50篇只收录了3篇。你可能会觉得这是运气不好,或者算法又抽风了。我们先停止这种猜测——这不是玄学,而是搜索引擎正在对你发送清晰的、可解读的信号。收录波动从来不是随机事件,它是你网站健康状况最灵敏的仪表盘。
首先得搞清楚:哪些波动是正常的,哪些是需要你立刻行动的警报。正常的波动有两种。
一是新站初期或大规模改版后,搜索引擎需要时间建立一个“认知模型”,收录量在第一个月里起伏不定是标准现象。
另一种是搜索引擎核心算法重大更新期间(比如2024-2025年间的一系列核心更新),整网的索引策略可能临时收紧或调整,你的站点会被短暂“重新评估”。
除此之外,如果你观察到的波动频繁、集中在特定类型页面、或者稳定运行的站点突然出现重要页面持续掉出索引的情况,那就不是波动,而是故障信号。
只看“收录总量”这个数字会被误导。它太笼统。真正能帮你定位问题的,是Google Search Console里一个常被忽略的报告项:“已抓取未编入索引”。
很多站长一看到收录量跌了就立刻去改内容、加外链,这是典型的用战术勤奋掩盖战略懒惰。你得先看懂搜索引擎到底在告诉你什么。
当Google的爬虫访问了你的页面(已抓取),却决定不把它放进数据库供用户搜索(未编入索引),就像一位审查员拿起了你的文件,翻了两页,然后直接扔进了碎纸机。原因不在送达环节,而在文件内容本身。
理解这个口径是你后续所有操作的基础。它会告诉你问题出在哪里:
问题一:爬虫来了,但技术障碍(比如服务器响应太慢)让它未能完整读取内容。救回时间通常在修复后3-7天。
问题二:爬虫顺利读取了内容,但认为内容价值不足(例如薄内容、重复率高),决定放弃收录。这需要系统性清理和重构内容,救回周期约15-30天。
问题三:站点因大量低质量页面或违规操作,触发了站点级的质量评估下调,重要页面被连带“连坐”不收录。这是最严重的情况,救回可能需要30-90天。
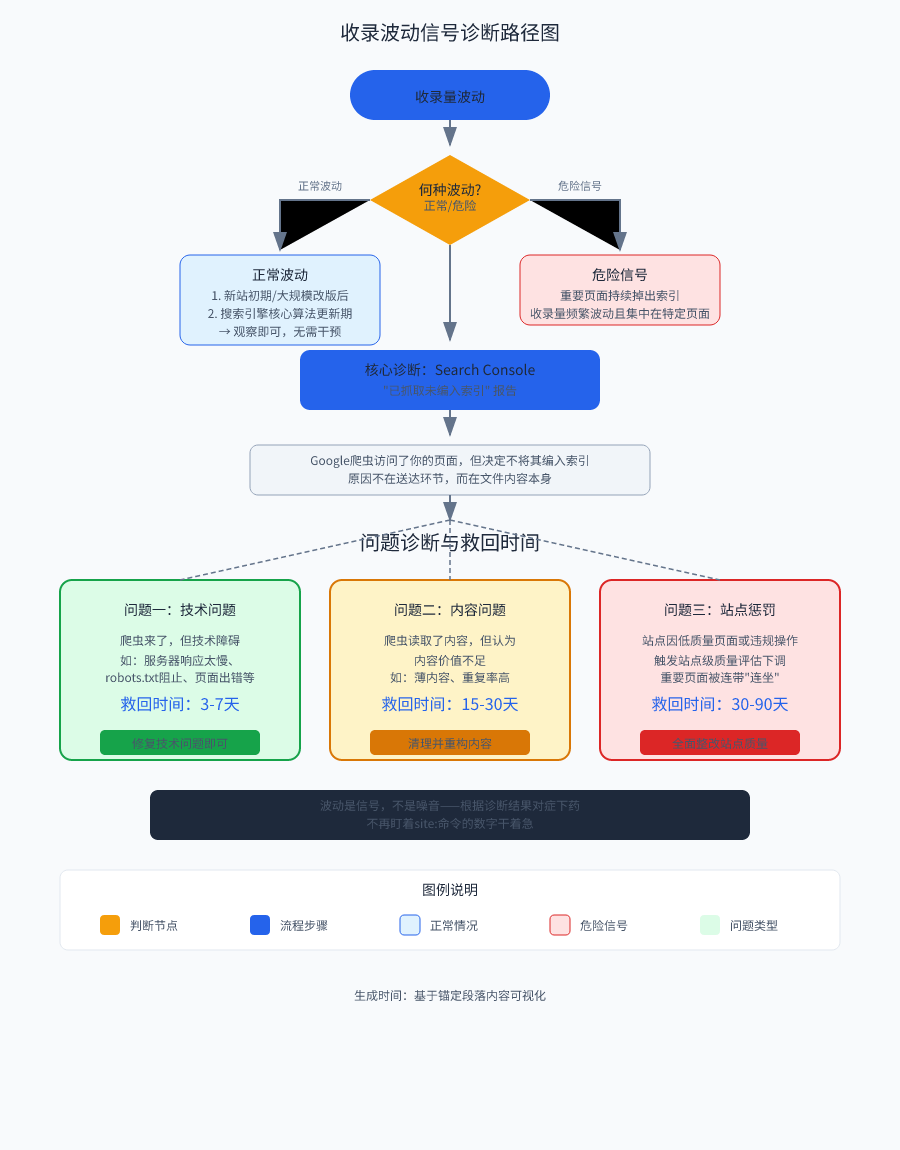
所以,别再盯着site:命令的数字干着急了。波动是信号,不是噪音。搜索引擎通过是否能将页面“编入索引”这个动作,已经给了你明确的故障分级。接下来,你需要学会看懂Search Console里那个沉默的报告项,并开始对症下药。
看懂Search Console的沉默
打开Search Console的“索引”报告,你会看到一个容易被忽视的数据项——已抓取未编入索引。这个数字背后藏着搜索引擎真正的态度:你以为它在干活,其实它已经在给你打分。
已抓取未编入索引的意思很直接:Google的爬虫来过了,把页面从头到尾读了一遍,然后决定——不收录。这个决定不是随机的,它基于爬虫对页面价值的判断。技术层面可能没问题,页面能打开、能读取,但搜索引擎认为这个页面不值得被用户搜到。
这就是为什么只盯着收录总量没有意义。总量跌了,你不知道是爬虫根本没来,还是来了但没入库。已抓取未编入索引这个指标,相当于给你的网站做了一次“质检抽查”——它告诉你有多少页面通过了抓取环节,却倒在了索引门槛前。
有些页面出现在这个报告里,完全正常,不用急着动手。Feed和RSS的链接就是典型例子。这类页面是网站向外部程序提供内容更新的入口,对用户搜索没有直接价值,Google主动不收录它们是正确行为。分页URL也是同样逻辑——比如/blog/page/2这类页面,Google需要抓取它来发现后续内容,但并不需要把它编入索引。至于那些打开只是一张图片、没有实质网页内容的链接,不收录更是标准操作。
但如果你在报告里看到大量重要页面——比如产品详情页、核心文章页、服务介绍页——出现在已抓取未编入索引的列表中,那就不是正常现象了。判断标准很简单:当这些本应被收录的重要页面在报告中的占比超过20%,意味着你的站点正在触发搜索引擎的质量预警。
20%不是一个随便的数字。低于这个比例,可能是局部页面的内容问题还有救回空间;超过这个比例,说明搜索引擎已经开始对你的整个站点产生质疑。这个阈值就像体温计的发热标准——过了这条线,身体肯定出了问题,必须优先处理。
一旦触发这个阈值,你的动作要快。先确认这些页面是否真的重要(产品页、文章页、有实际服务价值的页面),然后立即进入排查模式:是技术层面让爬虫无法完整读取,还是内容层面让爬虫觉得没有收录价值。这条判断线,直接决定了你接下来该修服务器还是该重写内容。
搞懂了哪些沉默是正常的,哪些沉默是危险的,你才不会被表面的数据变化带着跑。下一章我们分成两条线排查:先看技术层有没有拦路虎,再看内容层为什么被拒绝。
先检查这些技术拦路虎
既然看懂了GSC报告,发现重要页面确实被标记为已抓取未索引,先别急着改内容,可能是门坏了(技术问题)而不是房间乱(内容问题)。
技术拦路虎是硬门槛。服务器抽风、robots.txt写错一行、页面里藏了个noindex标签,这些都会让爬虫直接掉头走,根本不给你的内容打分的机会。排查要按优先级走,先解决“进不来“的问题,再谈“好不好“。
服务器稳定性:别让你的主机成为瓶颈
Google的爬虫没有耐心。当服务器响应时间超过1.5秒,或者可用率低于99.9%,爬虫会标记这个站点为“不稳定源“,暂时放弃抓取。这不是惩罚,是搜索引擎的资源管理策略——它不想把抓取预算浪费在经常打不开的页面上。
检查方法很简单。用UptimeRobot或Pingdom设置持续监控,看过去30天的可用率曲线。如果看到频繁的红点(宕机),或者响应时间图表经常突破1.5秒红线,先别管内容了,换主机或升级配置。服务器是底座,底座不稳,上面盖再漂亮的房子也白搭。
robots.txt与noindex标签:检查是否自己锁了门
这是最尴尬但也最常见的错误:你自己告诉搜索引擎不要进来。
打开你的域名根目录下的robots.txt文件。如果看到Disallow: /,这意味着你禁止了所有爬虫抓取整个网站。如果是Disallow: /blog/或Disallow: /products/,那就是特定栏目被屏蔽。每一个Disallow指令都要审查,确保没有误伤重要页面。
更隐蔽的是noindex标签。检查你的页面源代码,搜索meta name="robots" content="noindex"。这个标签明确告诉Google:“这个页面不要编入索引。“很多建站模板的默认设置、开发测试遗留、或者SEO插件的误操作,都会让这个标签留在正式页面上。用Screaming Frog或Sitebulb扫描全站,筛选出所有带有noindex标签的URL,逐个确认它们是否真的不需要被收录。
死链与错误重定向:别浪费抓取预算
死链率超过5%,搜索引擎会启动抓取预算削减机制。逻辑很直接:如果一个站点有5%以上的链接都是死胡同,爬虫会认为这个站点维护不善,减少分配给你的每日抓取配额。
用Search Console的“覆盖率“报告查看404错误数量。同时用Xenu’s Link Sleuth或Ahrefs Site Audit扫描全站死链。发现死链后,不要只是删除,要做301重定向到相关活页,或者返回410状态码(永久移除)。特别注意那些有大量内链指向的页面,如果它们变成404,会严重消耗抓取预算。
重定向链也要检查。A→B→C这样的多重跳转,或者A→B→A的循环跳转,都会让爬虫放弃。确保所有重定向都是直接的一步跳转,状态码返回干净利落。
JavaScript渲染阻塞:确保爬虫看到真实内容
现代网站大量依赖JavaScript加载内容,但Google的爬虫在抓取时可能执行不了或执行不全你的JS。如果核心内容(文字、图片、产品信息)是靠JavaScript动态插入的,而爬虫在“无JS环境“下看不到这些内容,它会认为这是一个空页面或薄内容页面。
用Google的“移动设备适合性测试“或“富媒体搜索结果测试“工具,查看页面在Google眼中的原始HTML。对比你浏览器里看到的渲染后内容,如果关键文字信息在原始HTML里不存在,只在渲染后才出现,你就遇到了JavaScript渲染阻塞。
解决方案包括服务端渲染(SSR)、预渲染(Prerendering)、或者确保关键HTML在服务器端就输出,JS只用来增强交互。不要让你的内容躲在JavaScript后面,爬虫不会耐心等待。
- 使用UptimeRobot或Pingdom监控过去30天服务器可用率,确认是否达到99.9%且响应时间稳定在1.5秒以内
- 打开根目录robots.txt文件,逐行审查所有Disallow指令,确认未误拦重要页面(如根目录或核心栏目)
- 使用Screaming Frog或Sitebulb扫描全站,筛选出所有含
meta name="robots" content="noindex"标签的URL,确认是否误留在正式页面 - 在Search Console覆盖率报告中查看404错误数量,使用Xenu’s Link Sleuth或Ahrefs扫描全站,确认死链率是否低于5%
- 检查全站重定向链路,确认所有跳转均为一步直达(A→B),无多跳链(A→B→C)或循环跳转(A→B→A)
- 使用Google移动设备适合性测试查看页面原始HTML,对比浏览器渲染后内容,确认核心文字信息在无JavaScript环境下可见
- 在Search Console中对关键页面执行实时URL检查,确认状态显示为“可索引“且无技术错误
把这些技术硬门槛全部扫清后,重新在Search Console里测试几个关键页面的“实时URL检查“。如果显示“可索引“且没有技术错误,但页面仍然出现在“已抓取未编入索引“列表里,说明问题不在门,而在房间里的内容质量。这时候该检查你的内容是否真的值得被收录了。
你的内容为什么被Google拒绝
技术检查全部通过,服务器稳如磐石,robots.txt也没拦路,但Search Console里“已抓取未编入索引“的名单还在增长。Google的爬虫确实来了,它推开门看了一眼,决定不收录。这时候该审视的不是服务器日志,而是页面本身的价值含量。
识别薄内容有个硬指标:页面主体字数低于300字且缺乏实质性信息。更隐蔽的是聚合页陷阱——只是把几篇文章标题罗列在一起,没有编辑撰写的原创总结或分类洞察,这也属于薄内容。Google判断“这页对用户没用“,直接拒绝编入索引。检查你的页面:如果删掉导航、侧栏和广告后,剩余文字不足300字,或者聚合页没有200字以上的原创分析段落,这就是被拒绝编入索引的直接原因。
UGC页面(用户生成内容)有个致命的时间差。论坛帖子在刚发布时往往只有问题描述,高质量回答还没出现,这时候Google来抓,看到的就是个空壳问题页,直接打上低质标签不予编入索引。等一周后有了精彩回答,Google短期内也不会再来,页面就卡在已抓取未编入索引状态。解决方法是给UGC增加“预审机制“:问题发布时先加上noindex标签,待有3条以上高质量回复后再移除标签开放索引,或者修复后主动提交请求编入索引。
重复内容率必须严格控制,特别是首页和栏目页,重复率需低于15%。模板化文字泛滥——比如每个产品页底部都塞着一模一样的公司介绍、每个栏目页顶部都是那段固定的欢迎词——会让Google认为这些页面缺乏独特价值。用查重工具扫描,删除或重写那些重复段落。15%是红线,超过这个比例,整站重要页面的索引状态都会开始波动。
最隐蔽的是站点级质量惩罚。当站内存在大量低质页面时,Google会对整个站点降级处理,连原本优质的重要页面也会被波及,出现“连带拒绝编入索引“。判断标准是:如果你的重要页面(产品详情页、核心文章页)在“已抓取未编入索引“报告中占比超过20%,同时站内还存在大量自动生成的标签页、空分类页,这就是站点惩罚信号。这时候单修一个页面没用,必须系统性清理。
搞懂这些软性拒绝的标准,你就拿到了诊断书。现在的问题是:面对满站的薄内容、重复页和错时被抓的UGC,你该按什么顺序动手才能最快见效?
按这个顺序执行救回操作
搞懂了技术和内容的根子问题,现在最怕的是一着急同时改所有东西。结果哪个都没改到位,搜索引擎还得重新适应,宝贵时间全浪费了。按优先级分层推进,才能用最短时间拿到最好效果。
第一步:先治立刻致命的硬伤(0-3天)
这个阶段只处理三件事,哪件不搞定都直接影响爬虫能不能进门。
服务器稳定性是第一条红线。响应时间超过1.5秒或者可用率低于99.9%的时候,Google会直接把这个站点列入“不稳定列表“,减少抓取频次甚至短期放弃。检查你的服务器状态监控,如果响应时间已经超标,马上联系主机商或者加带宽、换服务器。宁可多花点钱,也不要让爬虫因为加载慢而跑路。
然后查robots.txt文件。登录网站根目录找到这个文件,看有没有“Disallow: /“这种全站封禁的指令,或者误屏蔽了重要目录比如Disallow: /product/、/article/。同时用site:命令或者SEO工具全站扫描一遍,看哪些页面还残留着noindex标签。这两个问题是典型的自己把门锁上,Google想来都进不来。
最后处理死链。死链率超过5%会触发搜索引擎的抓取预算削减机制——简单说就是爬虫发现你站点上死链太多,判断这个站维护质量不行,减少来抓的次数和深度。直接把死链列出来,提交到Search Console的死链清理工具里,同时在网站上做好404页面,别让爬虫每次来都撞墙。
第二步:清理门户(3-7天)
技术命门守住了,现在解决内容层面的问题。
先做系统性移除低质量页面。前面章节已经说过判定标准:字数低于300字的薄内容页、只有标题列表没有原创分析的聚合页、纯粹为了抢关键词生成的空壳页面,这些一律处理。你有两个选择:有收录但质量低的页面,用noindex标签让Google不再索引;完全没有价值的页面直接从服务器删除。一次性不要删太多,每周处理20-30个页面比较安全,Google会逐步重新评估站点质量。
然后控制重复内容率。首页和栏目页的模板化文字必须删——比如每个产品页底部那段一模一样的公司介绍,每个分类页顶部那套固定的欢迎词。用查重工具扫一遍,重叠率超过15%的页面全部重写。重复内容是权重分散的隐形杀手,Google看到满站都在复制粘贴,会本能地降低对整个站点的信任度。
TDK优化也在这步完成。检查你所有重要页面的标题、描述和关键词标签,确保没有关键词堆砌的痕迹。每页标题只放1-2个核心关键词自然出现,保持完整可读的一句话形式。描述标签控制在150字以内,把页面核心价值说清楚,吸引用户点击的同时避免过度优化嫌疑。
第三步:重建核心页面价值(7-15天)
这阶段只针对两类页面动手:已经被判定为薄内容的核心页面,以及你绝对不想被降权的重点页面。
产品详情页、核心文章页、服务介绍页这些承载业务转化使命的页面,如果之前被划入“已抓取未编入索引“,说明内容价值不够。重新写的时候注意几个硬指标:单页字数不低于800字、必须有原创分析和独特见解、至少包含一个行业数据或者案例、段落之间有逻辑递进而不仅仅是并列罗列。Google现在对“实质性内容“的判断标准很清晰——你得比竞争对手多说出点什么,而不是把大家都能查到的信息再复述一遍。
UGC页面是特殊处理对象。论坛帖子、用户问答、评论页面在发布初期不要让搜索引擎来抓。等有至少3条以上高质量回复之后,再移除noindex标签开放索引权限。如果你的站点已经积累了大量只有问题没有回答的空壳UGC页面,系统性删除或者合并处理,不要让这些低质页拉低整个站点的质量评分。
第四步:重新分配权重流向(15-30天)
最后一步是关于权重分配的技术动作,前提是前面的步骤都已执行到位。
检查你的内链结构。确保首页获得的内部链接推荐占全站内链总量的30%以上——这不是玄学,内链数量直接决定页面在搜索引擎眼里的重要程度排序。如果你发现某些重要页面的内链数量连首页的十分之一都不到,这就解释了为什么那些页面权重上不去。用工具跑一遍全站内链统计,把重要页面的内链数量提升到这个比例。
同时检查所有重要页面有没有被加上nofollow标签。nofollow会让搜索引擎在爬取时跳过这个页面或者不传递权重,任何你不希望被降权的核心页面都不应该加这个标签。如果之前为了控制权重流向给某些页面加了nofollow,现在全部撤掉。首页、产品页、文章页都需要正常传递权重。
到这个阶段为止,如果前面所有步骤都执行到位,你的站点应该已经从“危险名单“里出来了。接下来要做的,就是验证这些动作到底起了多少效果。
六分钟内让页面重新被索引
前面按顺序做完了技术修复和内容重建,现在最忌讳的就是干等着Google自己发现。你需要主动验证这些改动到底管不管用,而且要用最快的速度确认,别等到一个月后才发觉白忙一场。
用Search Console的“请求编入索引“做分钟级验证
打开Search Console的“网址检查“工具,把你刚修复的页面URL贴进去。如果状态显示“已抓取未编入索引“,直接点击“请求编入索引“按钮。这不是什么高级技巧,而是Google给你的快速通道。提交后6到30分钟内,刷新页面看状态变化——如果变成“已编入索引“,说明爬虫认可了你的修复,这个页面已经回到索引库。如果30分钟后还是老样子,说明问题没解决彻底,你得回头检查前面的步骤哪一步没做到位。别嫌麻烦,逐个验证你的核心页面,特别是那些承载业务收入的产品页和文章页。
- 在 Google Search Console 中打开“网址检查”工具。
- 将修复后的核心页面URL(如产品页、文章页)粘贴到工具中,检查其页面状态。
- 若状态显示为“已抓取未编入索引”,则点击右侧的“请求编入索引”按钮提交。
- 提交后,等待6到30分钟,刷新该URL状态页面。
- 验证URL状态是否已成功变为“已编入索引”。如果未变,表明修复可能未到位,需回顾前述步骤。
- 登录 Search Console,在“站点地图”部分重新提交你的 XML Sitemap。
- 更新 Sitemap 文件内的
Lastmod标签日期至完成修复的当天。 - 针对需要快速恢复的重要页面,制定并执行每日新增3-5条来自高质量外链(如新闻源、行业媒体)的计划。
- 每日固定时间,检查 Search Console “覆盖范围”报告中“已编入索引”的数量变化,而非依赖
site:命令。
重新提交站点地图,别用旧文件糊弄
修复完技术问题和内容质量后,登录Search Console的“站点地图“功能,重新提交你的XML Sitemap。关键动作是更新Sitemap文件里的Lastmod日期,改成你完成修复的当天日期。Google看到这个时间戳就知道站点有实质性更新,会重新调度爬虫来评估。很多人只点“重新提交“按钮却不改文件里的日期,结果爬虫来了看一眼没变化就走了,白忙活。如果你用的是WordPress或类似CMS,确保生成的Sitemap自动包含了Lastmod标签,没有的话手动加上。
用外链缩短考核期
单靠内链和Sitemap让Google重新信任你的站点,周期可能要15到30天。如果你想把考核期压缩到一周内,需要外部信号加速。每天新增3到5条来自新闻源或行业垂直媒体的优质外链,指向你刚修复的重要页面。这些外链不需要是首页链接,直接链到具体的产品页或文章页效果更好。行业媒体的新闻稿、垂直论坛的推荐帖、合作伙伴的资源页都可以。Google看到权威第三方在引用你的页面,会把这个信号作为“质量背书“,大幅缩短重新评估的时间。
💡 小贴士:避免来自链接农场、垃圾站点或无关行业的外链,Google不仅不认可这类链接,还会将其视为质量信号下降的证据。优先选择与你的业务直接相关且本身有SEO流量的平台。
监控正确的指标,别看site:命令
验证阶段最危险的误区是看site:domain.com的返回结果。这个数字极其不稳定,缓存更新有延迟,经常给你虚假的好消息或坏消息。正确的做法是每天固定时间登录Search Console,进入“覆盖范围“报告,只看“已编入索引“这个具体数字的变化。前一天是1500条,今天变成1520条,说明修复生效了;如果连续三天没变化甚至还下降,说明前面的救回动作有漏洞。把这个数字做成简单的Excel追踪表,每天早上花两分钟记录,比你在Google搜索框里反复试site:命令靠谱一百倍。
收录恢复了不代表结束。当你看到“已编入索引“的数字开始稳定增长,说明抢救成功,但这时候恰恰最容易松懈。你需要建立一套机制,防止再次掉进那种忽高忽低的波动陷阱。
收录稳定后的防 fragile 机制
收录恢复后的第一周最容易松懈。看着Search Console里的“已编入索引“数字稳定回升,你会觉得终于可以松口气了。但这恰恰是最危险的时候——你没有建立防复发的机制,下一次波动可能只是因为某次不经意的操作。
修复是一次性的急救,但稳定收录需要一个持续运行的标准化作业程序(SOP)。你需要把前面六个章节的临时动作,变成三套固化下来的日常或定期检查机制,让整个网站运营进入一个“发现问题→自动预警→标准处理“的良性循环。这不需要多高深的技术,需要的只是纪律和几个关键的执行节点。
第一套机制:让每一篇新内容在发布前就通过质量安检
别再凭感觉发文章了。每次点击“发布“按钮前,用一个五分钟的检查清单过一遍,卡住那些日后会让Google摇头的薄内容。
首要检查原创度和信息增量。 别用自欺欺人的伪原创工具。简单问问自己:这篇文章除了复述公开信息,有没有提供我们自己的数据、案例拆解或行业观察?如果答案都是否定的,这篇内容的索引优先级在Google眼里天生就低。对于资讯聚合类或产品页,要求必须有200字以上的原创分析或使用场景补充。
字数不是唯一标准,但必须超过500字的实质门槛。 对于文章页,正文(不含导航、侧边栏等模板文字)必须达到500字以上。对于产品页,如果客观描述不足300字,必须补充用户评价、使用教程或场景化文案来增加信息密度。你可以为产品、文章、FAQ等不同内容类型,在后台编辑器里设置最低字数红线,发布时不达标就卡住。
关键词密度需要监控,但目标是自然而非达标。 SEO插件显示的密度值超过3%时,就要回头通读一遍,删除那些生硬的堆砌。自然的写作应该是围绕主题展开,而不是围绕关键词造句。
- 确认内容包含至少一条原创数据、案例拆解或行业观察(非单纯复述公开信息)
- 检查资讯聚合页或产品页是否已补充200字以上原创分析或使用场景描述
- 核实文章页正文(不含导航、侧边栏等模板文字)字数超过500字
- 核实产品页客观描述不足300字时,已补充用户评价、使用教程或场景化文案
- 检查SEO插件显示的关键词密度是否低于3%,若超标则通读并删除生硬堆砌表述
- 确认后台编辑器已为不同内容类型设置最低字数红线,确保不达标内容无法发布
这套清单应该做成一个可勾选的表单,由编辑或运营人员在发布前执行。它消灭的是内容质量上的系统性风险。
第二套机制:用自动化工具取代人工巡检,发现技术问题
你不会每天手动检查服务器,但机器可以。技术问题是沉默的杀手,等你自己发现时,收录通常已经掉了一周。
设置服务器可用率与响应时间的监控告警。 使用UptimeRobot或类似工具,每五分钟检查一次服务器,当响应时间超过1.5秒或当日可用率低于99.9%时,立即发送告警到你的邮箱或钉钉群。这意味着Google爬虫在抓取你的站点时已经遇到了明显的延迟或失败,必须立刻处理。
每周自动扫描全站死链。 手动检查不现实。配置Screaming Frog或Xenu这类工具的计划任务,每周日凌晨自动爬一遍全站,生成死链报告(HTTP状态码为4xx)。重点关注死链率是否超过全站链接数的5%。这份报告每周一早上出现在你的收件箱,你只需要根据它来批量提交死链删除或设置301重定向。
定期检查robots.txt与noindex标签的意外变更。 每次网站改版、插件更新或新功能上线后,很容易因为疏忽而在robots.txt里多写一行Disallow,或在页面模板里残留noindex标签。可以编写一个简单的脚本,每隔24小时获取一次你网站的robots.txt文件,与一个基准版本做对比,有变动就告警。同时,每月用SEO爬虫工具扫描一次全站,检查所有重要页面的元标签中是否意外出现了noindex。
💡 小贴士:配置监控告警时,不仅要通知“服务器出问题了”,更要明确写出具体原因(如“响应时间超过1.5秒”)和影响面(如“首页及产品列表页抓取失败”),这能帮你在一分钟内定位问题根源,而不是浪费半小时去排查。
技术监控的核心是把需要“想起来才去检查”的事情,变成“出问题它来通知你”。
第三套机制:建立收录健康状况的每周预警雷达
每周一早上,花十分钟在Search Console里做一次固定检查。这不是为了看总量,而是为了发现异常趋势,在问题扩大前介入。
核心动作是查看“覆盖范围”报告。 重点不是“已编入索引”的总数(这个变化是结果),而是“排除”部分里“已抓取 – 目前未编入索引”这项的数量变化。计算出本周这项的数量比上周增加了多少百分比。
设定明确的预警阈值。 如果“已抓取未索引”的URL数量每周增长率超过10%,就是一个明确的早期预警信号。这说明Google对你的站点又开始产生“质量疑虑”,新抓取的页面它选择暂时不收了。这时候不要慌,立刻启动审查流程:
- 样本检查: 从这份报告里随机抽取10-20个新出现的URL,检查它们是否属于第一章提到的正常情况(如分页、Feed)。如果大部分是产品页或文章页,进入下一步。
- 内容诊断: 检查这些页面是否触发了前面章节说的薄内容、高重复率等问题。
- 技术复核: 确认这些页面的服务器响应、爬虫可访问性无异常。
这个审查流程本身也是标准化的,可以在一个小时内完成初步判断。关键在于“每周一次”的纪律和执行“增长率超过10%就触发”的果断。
当你把内容发布清单、技术监控告警和每周收录审查这三件事跑通,收录就不再是一个需要你时刻紧盯、忽喜忽忧的玄学指标。它会变成一个由清晰规则和自动化工具守护的稳定系统。你从“救火队长”变成了“系统巡检员”。
最后,把这篇文章的所有步骤,特别是本章的三套标准作业程序,整理成一张可打印、可分享的流程图清单。张贴在团队的协作空间里,或者做成新员工的入职培训材料。下一次当你或同事再问“收录怎么又掉了”,答案不再是猜测,而是启动一次标准化的诊断流程。